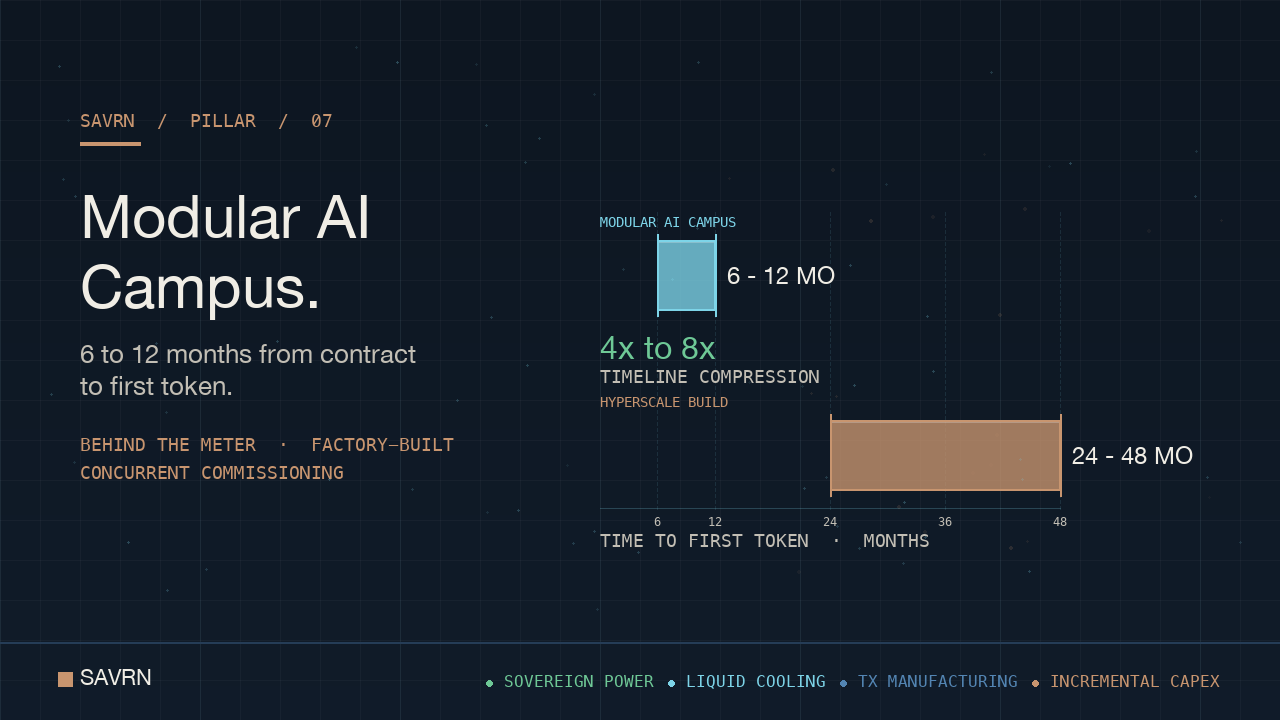
The modular AI campus is the architecture enterprise buyers reach for when they cannot wait four years for compute. In particular, hyperscale builds still average 24 to 48 months from groundbreak to first token. Moreover, the grid queue alone runs five years on the median pr project. It collapses that window into 6 to 12 months by manufacturing the compute block in a factory, generating the power on-site, and running every workstream in parallel.
About SAVRN. SAVRN is the operator of an off-grid sovereign AI infrastructure campus model — owned power generation, owned compute, closed-loop liquid cooling — deployed in 6 to 12 months versus the 24-to-48-month industry standard, with active developments in California, Texas, Colorado, Nebraska, Panama, and Barbados.
This piece walks the engineering of that compression. Specifically, it shows what gets prefabricated, what gets eliminatated, and what tradeoffs the buyer accepts in exchange for speed. It compares modular blocks to the hyperscale model across eight dimensions that actually matter at procurement, then names the buyers each architecture serves.
The takeaway up front. Notably, this approach is not a smaller hyperscale. It is a different architecture, built to a different clockspeed, sized for a different buyer. The hyperscaler can amortize 48 months across a portfolio. A sovereign buyer, a defense prime, or an enterprise racing a model release window cannot. For that buyer, the modular AI campus is the only architecture that matches the velocity AI itself moves at.
Why the modular AI campus exists in 2026
The modular AI campus exists because the conventional build path stopped working. On the whole, two structural blockers, the grid queue and the constnstruction timeline, stretched hyperscale delivery past the point where AI buyers could absorb the wait. Both problems compounded in 2024 and 2025. By 2026 they had reshaped the buying conversation.
The interconnection backlog drove the modular pivot
Roughly 2,500 GW of generation and storage capacity sits in U.S. interconnection queues today, per Lawrence Berkeley National Laboratory’s queued capacity tracker. Importantly, the median project waits five years between request at and commercial operation. Of every project that filed between 2000 and 2019, only 13 percent reached commercial operation by the end of 2024. Seventy-seven percent withdrew. The remaining 10 percent are still stuck.
Those numbers describe the worst of the queue, not the best. However, they describe what every new hyperscale faces when it asks for grid capacity at scale. In fact, generating power behind the meter routes around the queue ene queue entirely. As a result, it ships when the equipment ships, not when the utility’s substation upgrade lands.
The construction problem this architecture solves
Stick-built data centers also stalled on the construction side. IEEE Spectrum’s modular deployment review reports field installation of a modular block in 2 to 3 weeks against 15 weeks for the equivalent stick-built shell. Industry-wide, modular construction methods cut total schedule by 30 to 50 percent on data center projects. That is the kind of compression that turns a 36-month build into an 18-month build, or an 18-month build into 9 months.
Therefore, this architecture is not a niche format. In fact, it is the architectural answer to two structural blolockers the conventional model cannot solve: queue time and stick-built duration. Buyers who needed a build path measured in months adopted it. The architecture followed.
The 48-month problem hyperscale cannot solve
The hyperscale build is a particular kind of problem. In particular, three workstreams compound. Specifically, permitting takes 12 to 24 months in many jurisdictions. Power interconnection takes 24 to 60 months. Stick-built construction takes 18 to 30 months on top. None of these are concurrent in the conventional sequence. Permits gate construction. Construction gates power energization. Power energization gates commissioning. As a result, the timeline is the sum, not the maximum.
Permitting drags the front of the build
Local permitting is rarely the headline blocker, but it compounds. On the whole, a new substation needs a separate environmental revview. The water cooling plant requires its own use permit. On top of that, a 200 MW campus on greenfield land needs zoning, traffic, lighting, sound, and stormwater approvals. Each one is a sequential process. Each one can lose a quarter to a comment period.
Modular AI campus designs reduce this surface. Specifically, a factory-built unit collapses many of the on-site approvals because the unit itself is permitted as equipment, not as a building. As a result, the permitting envelope shrinks to the pad, the power source, and the connectivity. That alone often saves 6 to 9 months.
Power interconnection sits on the critical path
Once permits clear, power becomes the long pole. Moreover, utilities are signaling regional capacity shortages as earls as early as 2026 in several U.S. markets. Lead times on high-voltage transformers and switchgear hold above 18 to 24 months. Even when the utility says yes, equipment delivery and substation work routinely stretch into 30+ months. The hyperscaler cannot start commissioning compute until the substation energizes.
By contrast, behind-the-meter generation breaks this dependency. On the whole, the Energy Institute at Haas notes that on-site generneration can compress a multi-year interconnection wait into a timeline measured in months. Therefore, the architecture that owns its power source decouples from the utility’s queue. It still talks to the utility for backup or export, but the AI workload is not blocked on it.
Stick-built construction is sequential by nature
The third workstream, the building itself, is the part everyone sees. Indeed, foundation, shell, MEP rough-in, raised floor, fit-out.-out. A 50 MW shell takes 12 to 18 months for the structure alone. In particular, cooling plants, fluid systems, fire suppression, and security run another 6 to 9 months. Then commissioning. The sequence is hard to compress because each trade gates the next.
Modular fabrication moves most of that sequence into a controlled factory environment, where it runs in parallel with the on-site civil work. Specifically, as a consequence, when the modules arrive, the pad i is already cured, the power feed is already energized, and the network drop is already pulled. The on-site sequence becomes setting, connecting, and commissioning. That is what compresses 30 months into 6.
What a modular AI campus actually is
A modular AI campus is not a shipping container with servers. Furthermore, it is a factory-built integrated unit that contains s the power, the cooling, the compute, and the controls in one envelope. The unit ships, gets set on a pad, gets connected to a fuel source or generation tie-in, gets connected to fiber, and runs.
The factory-built advantage
Factory fabrication compounds three advantages. First, the build environment is controlled. In addition, weather does not move the schedule. Trades do not stack. Quality control runs at the line, not at the pad. Second, the work is repeatable. The hundredth unit ships faster, cleaner, and cheaper than the first. Third, the work is concurrent with site preparation. While the unit is being welded, plumbed, and wired offsite, the pad, the power feed, and the fiber drop are being prepared on site. Both clocks run in parallel.
Therefore the on-site critical path collapses to a small set of items: pad, fuel feed, fiber, and commissioning. Notably, the complex parts of the build, the parts that histortorically caused trade clashes and weather delays, no longer happen on site. They happen in a factory in Texas, on a clock that the manufacturer controls.
Power, compute, and cooling unified
The integrated nature of the modular model matters as much as the speed. Notably, conventional hyperscale builds source the power plant, the chiant, the chiller plant, the white space, and the compute from different vendors with different schedules. Each handoff is a delay risk. Each scope boundary is a finger-pointing surface during commissioning.
By contrast, the modular approach integrates these layers under one engineering authority. As a result, the cooling loop is sized to the rack densities the compute will actually run. Specifically, the power generation is sized to the worst-case AI tr training profile, not to a generic IT load. Commissioning is one process, not four.
Rack-level power and cooling sized for AI workloads
The internal architecture of modular deployments is sized for AI training and inference workloads, not for legacy enterprise IT. In fact, rack-level power and cooling is engineered for high-deh-density AI configurations. Liquid cooling is the default, not the upgrade path. Power delivery is sized for sustained training loads, not for the lower averages a colocation tenant might run. In short, the modular model is purpose-built for AI compute the way a hyperscale shell, originally designed for cloud services, is not.
How a modular AI campus compresses the timeline
The compression has a structure. In fact, it is not magic. It comes from three engineering decisions: parallelism, prefabrication, and behind-the-meter power. Together, these collapse the sum-of-workstreams into the maximum of the longest one.
Concurrent rather than sequential workstreams
The conventional build runs permitting, then power, then construction, then commissioning. Indeed, each gate stops the next. By contrast, a modular AI campus runs them concurrently. Permits run while modules are being built. Pad work runs while transformers are being shipped. Fiber gets pulled while modules are in transit. As a consequence, the on-site clock starts running when modules arrive, not when ground was broken.
Week 1 to week 26 in practice
For a 50 MW campus, the schedule looks like this in practice. Furthermore, weeks 1 to 4: site finalization, fuel and fiber surveysrveys, permit pre-application. Weeks 5 to 12: pad and foundation, fuel feed installation, fiber drop. In parallel: module fabrication. Weeks 13 to 16: module delivery and setting. Then weeks 17 to 22 cover connection, fuel commissioning, and power-on. Finally, weeks 23 to 26 cover compute commissioning, network burn-in, and first token. That is six months from contract to first token, on the design side.
Real projects vary. Notably, the campus with a complex permitting jurisdiction or or an unusual fuel arrangement extends to 9 to 12 months. However, the upper bound of 12 months is still a quarter of what the conventional hyperscale build asks of a buyer. That is the gap that defines the buying decision.
Where the time savings actually come from
To reduce the build to a single number, the savings break down roughly as follows. Indeed, twelve to 24 months saved on grid interconnection by genby generating power on site. Six to 12 months saved on construction by moving stick-built work into a factory. Three to 6 months saved on commissioning by integrating the layers under one engineering authority. Total: 21 to 42 months recovered, against a 24 to 48 month conventional build. The math holds.
Modular AI campus vs hyperscale: 8-dimension comparison
Speed is the headline. It is not the whole story. The modular AI campus differs from a hyperscale data center across eight dimensions that show up in procurement and operations. Some favor the modular approach. Others favor the hyperscale. Buyers should understand both columns before choosing.
1. Above all, speed to first token
Modular: 6 to 12 months. Hyperscale: 24 to 48 months. The 4x to 8x compression is the cleanest single metric. For a buyer racing a model release, a procurement deadline, or a market window, this dimension dominates everything else. For a hyperscaler building 5-year capacity in a 10-year amortization model, it matters less.
2. Capex profile and incremental scaling
Modular: capex flows in increments matched to module deliveries. A 200 MW campus does not need 200 MW of capital up front. By contrast, hyperscale projects commit substantial capital before any compute earns revenue. As a result, modular deployments is friendlier to buyers without hyperscaler-grade balance sheets, including sovereign customers, defense primes, and growth-stage AI companies.
3. Power architecture and grid dependence
Modular: behind-the-meter power generation is the default. The campus operates whether or not the utility’s queue moves. Hyperscale: grid-tied at scale. Even hyperscalers experimenting with on-site generation typically rely on the utility for the bulk of their megawatts. Therefore, the sovereignty profile of the two architectures diverges sharply on this dimension.
4. Cooling architecture and density ceiling
Modular: liquid cooling at the rack, sized for high-density AI workloads from day one. Hyperscale: typically air-cooled or hybrid, retrofitting liquid as AI workloads arrive. The modular unit pays this cost up front. By contrast, the hyperscale pays it again at retrofit. As a design output, the density ceiling of the modular unit reflects intent. The density ceiling of the hyperscale shell, on the other hand, is a constraint.
5. Site flexibility and geographic footprint
Modular: deployable on smaller parcels, often outside hyperscaler-favored geographies. A 50 MW unit fits on 20 to 50 acres. Hyperscale: 500+ acres for a multi-hundred-megawatt site. The architecture opens land in Texas, Colorado, Nebraska, and California that does not work for a hyperscale. As a consequence, the buyer chooses among more sites, more jurisdictions, and more permitting climates.
6. Sovereignty and security profile
Modular: physically isolated by default. Single-tenant. The buyer owns the perimeter, the power, the compute, and the data path. Hyperscale: typically multi-tenant or hyperscaler-operated. Sovereignty is contractual rather than physical. For defense, regulated, and sovereign buyers, this model offers a cleaner compliance posture. For commodity workloads, the difference matters less.
7. Hardware roadmap responsiveness
Modular: each new module reflects the current generation of compute. New modules ship as new GPU platforms become available. By contrast, a hyperscale shell built in 2024 still has 2024-era cooling and power assumptions in 2028. The modular architecture refreshes one module at a time. The hyperscale refreshes one shell at a time. As a result, the modular architecture tracks the hardware roadmap more closely.
8. Operational scale and unit economics
This is the dimension where hyperscale wins. At 1 GW or more on a single campus, hyperscale unit economics on power, cooling, and ops compete favorably with anything else. The modular model does not aim at that scale on a single site. Instead, it aims at distributed scale across many sites. For a buyer that genuinely needs 1+ GW under one fence, hyperscale is still the right answer. For everyone else, modular blocks equals or exceeds the unit economics by avoiding the carrying cost of an unfilled shell.
Where the modular AI campus model wins
Three buyer archetypes drive the modular AI campus market in 2026. Each one needs the architecture for a different reason. Each one accepts the tradeoffs because the alternative is unacceptable.
Sovereign AI buyers
National and sub-national governments standing up domestic AI capability cannot wait 48 months. They also cannot route their workload through a hyperscaler whose ultimate ownership and supply chain sit outside the buyer’s jurisdiction. As a consequence, the modular approach is the only architecture that delivers both speed and full-stack ownership in the same package. Sovereign buyers in Latin America and the Caribbean, including Panama and Barbados, are evaluating modular deployments specifically for this combination.
Defense procurement buyers
Defense buyers face the same speed-and-sovereignty constraint, plus a third: physical isolation. The modular deployments delivers all three. A factory-built, single-tenant, behind-the-meter unit is the cleanest match for compliance regimes that require air-gapped or classified workloads. Hyperscalers can offer government regions, but a sovereign campus is structurally easier to certify than a multi-tenant shell.
Distributed enterprise AI
Large enterprises running AI training across multiple geographies, often for data residency or latency reasons, fit the modular unit profile naturally. They need 50 to 200 MW per location, not 1 GW under one fence. They need each location energized inside a 12-month planning horizon. Therefore, the per-site economics, the per-site speed, and the per-site sovereignty all line up. A distributed modular footprint matches the workload distribution.
Where hyperscale still makes sense
The modular AI campus is not the right answer for every buyer. In particular, the hyperscale model still wins in a specific zone: very large, single-site, multi-year amortization, where the buyer can absorb a 48-month wait and operates at the scale where unit economics flip. That is the hyperscaler’s core business, and they are very good at it.
Hyperscaler portfolio economics
Hyperscalers will spend roughly $600 billion on data center capex in 2026, by CreditSights’ aggregated estimates. They run that capital across portfolios of dozens of campuses, smoothed over 10-year horizons. For that buyer, an 18-month variance on any single site averages out across the rest. The modular model does not need to compete with that buyer. It serves the buyer who cannot smooth capex across a 30-site portfolio and a 10-year horizon.
The 1+ GW single-fence question
Some workloads genuinely need 1+ GW of compute under one fence with one fabric. Those are usually frontier model training runs at the largest labs. The modular model serves the next tier down: 50 to 500 MW per site, often distributed across multiple sites. For the 1+ GW single-fence customer, hyperscale is the right architecture, and modular is not trying to compete on that dimension.
How to evaluate a modular AI campus partner
Speed is meaningless if the partner cannot execute. Buyers evaluating a partner should focus on four dimensions. Each one separates marketing claims from delivery capability.
Power architecture due diligence
Ask how the partner generates power. Then ask how the fuel arrives. Finally, ask what the redundancy looks like. A partner that says behind-the-meter but cannot describe the fuel arrangement, the runtime, or the failure modes is not actually behind the meter. Notably, the power architecture is the foundational claim of the modular model. It needs the most engineering specificity in the answer.
Manufacturing depth and supply chain
Ask where the modules are built. Then ask who controls the line. Finally, ask what the unit cadence is. A modular partner that depends on a third-party manufacturer for the unit itself has the same supply-chain exposure that the hyperscale model has. By contrast, a partner with integrated manufacturing controls the schedule end to end. Domestic manufacturing in Texas, for instance, materially reduces logistics and tariff risk against overseas equivalents.
Cooling and density ceiling
Ask what the rack density ceiling is. Ask how the cooling system handles the next generation of compute. A modular unit that ships in 2026 should be sized for the AI hardware that will land in 2027 and 2028. A partner that designed cooling for 2022-era density is selling a unit that will be obsolete inside the depreciation window.
Deployment record and references
Finally, ask for a deployed unit count. Ask for a delivered timeline. Ask for an operational reference. The such a campus market includes a long tail of partners who can describe the architecture but cannot point to a unit running in production. The buyer should privilege partners with field-proven deployment records over partners with the best slide decks. The architecture is real. The execution is the variable.
How SAVRN delivers the modular AI campus
SAVRN occupies the modular AI campus category as an integrated operator. The architecture is end to end: behind-the-meter power generation, factory-built compute and cooling modules, liquid cooling sized for high-density AI workloads, and a deployment cadence measured in months. SAVRN’s sovereign AI infrastructure approach treats power, compute, and cooling as a single design problem solved once, then replicated.
The manufacturing is integrated, not outsourced. SAVRN’s Intelliflex platform builds modular blocks in Texas, on a line SAVRN controls. As a result, the unit cadence is predictable, the supply chain is domestic, and the engineering authority for the power, the compute, and the cooling sits inside one company. That is the operational difference between this architecture claim and the architecture delivery.
The geographic footprint follows the buyer. SAVRN is actively evaluating sites in Texas, California, Colorado, and Nebraska, and is in conversation with sovereign buyers in Panama and Barbados. The SAVRN doctrine treats the architecture as the natural unit of deployment: small enough to ship, large enough to matter, fast enough to land inside an AI buyer’s planning horizon.
The economics of the architecture over five years
Speed has an economic value. A modular AI campus that delivers 50 MW of compute 24 months earlier than a hyperscale build generates 24 months of additional revenue, training cycles, or competitive position. That economic value frequently dwarfs the marginal capex difference between the two architectures. Buyers who model the deployment timeline as a financial variable rather than a project-management variable end up with very different decisions.
The cost of waiting
Cloud GPU pricing for sustained training workloads varies, but at typical 2026 rates, every month of delay on a 50 MW workload costs millions in incremental cloud spend. Multiply across 24 months. The cost of waiting for a hyperscale build is rarely captured in the procurement model. By contrast, the modular model build absorbs that cost as schedule compression. As a consequence, the buyer sees the savings in the cloud bill, not in the capex line.
Capex layered to demand
The modular approach also matches capex to actual demand. A buyer who needs 100 MW in year 1 and another 100 MW in year 3 deploys two phases. Conventional hyperscale projects often commit substantial capital up front for capacity that will sit idle. As a result, the modular model carries less unfilled inventory risk. That is a structural advantage, not a marketing claim.
Common objections to the modular AI campus
Buyers raise three objections in nearly every such evaluation. Each one has a real answer. None of them changes the underlying architecture, but the answers determine whether the partner is credible.
Objection 1: Density ceiling
The objection: a modular unit cannot match a hyperscale shell on rack density. The answer: modular deployments designed in 2026 for AI workloads ships with cooling and power sized for high-density configurations from day one. Many hyperscale shells built in 2022 cannot match that density without retrofit. Notably, density ceiling is a design output of the modular approach, not a constraint of its size.
Objection 2: Operational scale
The objection: a 50 MW campus cannot match the operational scale of a 500 MW hyperscale. The answer: at the per-site level, the hyperscale wins on unit economics for ops, power purchase, and cooling at multi-hundred-megawatt scale. At the buyer level, a distributed footprint of multiple the modular unit sites delivers comparable economics with better resilience, better data residency, and faster deployment per site.
Objection 3: Vendor lock-in
The objection: the campus locks the buyer into one vendor’s units. The answer: every infrastructure decision is a vendor decision, hyperscale included. The modular deployments reduces lock-in on the workload side because the buyer owns the compute and the data. Buyers who care about lock-in should ask about hardware refresh, module portability, and exit terms. The vendors who answer these questions transparently are the credible ones.
What buyers should have ready before evaluating a modular AI campus
The modular partner runs faster when the buyer arrives prepared. Three pieces of information collapse the procurement timeline materially. Buyers who arrive without them slow themselves down, not the partner.
Workload profile and capacity targets
Define the workload. Training, inference, or mixed. Sustained or bursty. Confidential or commercial. Define the capacity, in MW, at year 1 and year 5. The modular partner can size the unit, the cooling, and the power generation tightly when this is concrete. Vague targets produce conservative sizing, which produces overbuilds.
Site control and power data
Bring control of the land. Even a 24-month option is enough to start. Bring whatever data exists on existing power, fuel availability, and fiber proximity. The modular partner can run a 48-hour site screen with this. Buyers who have not started the land question burn 6 to 12 weeks before any real engineering can begin.
Use-case clarity and compliance posture
Name the use case. Sovereign, defense, regulated, or commercial. Each profile changes the security, compliance, and isolation requirements of modular blocks. Buyers who arrive with a fuzzy “we need AI compute” brief get a generic proposal. Buyers who arrive with a defined use case get an engineered solution. The difference is weeks of cycle time.
Connecting to the broader AI infrastructure stack
The modular AI campus does not exist in isolation. It connects upstream to power generation, downstream to applications, and laterally to the rest of the buyer’s AI stack. The architecture’s value compounds when the rest of the stack is engineered to match.
Power supply and the circular economy
Behind-the-meter generation is the upstream connection. The campus that integrates with on-site power becomes part of a closed-loop system: fuel in, electricity through compute, waste heat reused or rejected, water managed in a closed loop. As a result, the campus stops being a pure consumer of grid resources and becomes a self-contained energy and compute system. That is the SAVRN doctrine in compressed form.
Connectivity and data sovereignty
The downstream connection is fiber. Such a campus needs diverse, low-latency fiber paths to the workloads it serves. For sovereign buyers, the fiber routing also matters: data sovereignty requires that the data path stays inside the relevant jurisdiction. The modular partner that designs for both reach and routing reduces a class of compliance risk that hyperscale buyers often discover late.
Hardware refresh and the AI roadmap
A lateral connection is the AI hardware roadmap. Notably, the next generation of accelerators is already telegraphed. The modular AI campus refreshes one module at a time, which means the campus tracks the roadmap module by module rather than shell by shell. By contrast, the hyperscale shell is harder to retrofit because the building, the cooling plant, and the power feed were sized once. It is the architecture that ages most gracefully against an accelerating hardware curve.
Modular AI campus FAQ
What is a modular AI campus?
A modular AI campus is a factory-built, integrated infrastructure unit that combines power, cooling, compute, and controls in a single envelope, sized for AI workloads. The unit is manufactured offsite, shipped to the deployment location, and connected to a fuel source and fiber. It collapses a 24 to 48 month conventional build into 6 to 12 months by running fabrication, permitting, and site work in parallel.
How long does it take to deploy a modular AI campus?
Most such deployments land between 6 and 12 months from contract to first token. Six months is achievable when permitting is favorable, the fuel source is readily available, and the site has fiber proximity. Twelve months is the realistic upper bound for harder jurisdictions or unusual fuel arrangements. Both timelines are well below the 24 to 48 months typical of conventional hyperscale builds.
How does a modular AI campus avoid the grid interconnection queue?
The modular model generates power behind the meter, on site, rather than relying on utility grid interconnection. As a result, the AI workload is not blocked on the utility’s queue, which currently averages five years for the median project nationally. The campus may still tie to the grid for backup or export, but the compute energizes when the on-site generation comes online, typically inside the 6 to 12 month window.
What size is a typical modular AI campus?
A typical the modular approach ranges from 25 to 200 MW per site, with deployments scaling through additional modules over time. Smaller units, in the 5 to 25 MW range, suit edge or sovereign deployments. Larger configurations, in the 200 to 500 MW range, suit enterprise or distributed-training workloads. Modular construction means the campus expands incrementally rather than committing full capacity at day one.
Is a modular AI campus more expensive than a hyperscale build?
The capex per megawatt is comparable to a conventional build at scale, but the schedule compression and incremental capex profile favor modular deployments for most non-hyperscaler buyers. The buyer also avoids carrying-cost on unfilled shell capacity. When the cost of delay is included, where every month of waiting represents incremental cloud spend, this model is frequently the cheaper option on a fully loaded basis.
What workloads run on a modular AI campus?
AI training, AI inference, scientific computing, and high-performance computing workloads all run on the modular unit. The architecture is sized for sustained high-density compute rather than legacy enterprise IT. Mixed workloads work well when the cooling and power are sized for the worst-case profile, typically large-model training. Inference-heavy buyers can opt for slightly different module configurations, but the underlying architecture is the same.
Can a modular AI campus support classified or air-gapped workloads?
Yes. The single-tenant, physically isolated, behind-the-meter design of the campus is structurally well suited to classified, air-gapped, or sovereign workloads. The buyer owns the perimeter, the compute, and the data path. Compliance certifications still depend on the partner’s specific controls, but the architecture itself supports the strictest sovereignty requirements that hyperscale multi-tenancy makes harder.
How does a modular AI campus handle hardware refresh?
Hardware refresh on this model happens module by module, rather than shell by shell. As newer compute platforms ship, individual modules are upgraded or replaced with the current generation. By contrast, hyperscale shells are sized once and retrofit only with significant disruption. The architecture tracks the AI hardware roadmap more closely because the unit of refresh is small enough to swap on a normal operations cycle.
Where can a modular AI campus be deployed?
A modular AI campus can be deployed nearly anywhere with a suitable pad, a fuel source for behind-the-meter generation, and fiber connectivity. Smaller land parcels, often 20 to 50 acres for a 50 MW campus, expand the geographic footprint well beyond hyperscaler-favored regions. Active deployment geographies include Texas, California, Colorado, and Nebraska in the U.S., with sovereign deployments evaluated in Panama and Barbados.
Who should not buy a modular AI campus?
Buyers who genuinely need 1+ GW of compute under a single fence with one fabric, typically the largest frontier model labs, are better served by hyperscale. Buyers with hyperscaler-grade balance sheets and 10-year amortization horizons can absorb the conventional 48-month build economics. Everyone else, including sovereign, defense, regulated, and most enterprise AI buyers, fits the modular AI campus profile better than the hyperscale alternative.
Continue exploring
- From Site to First Token: SAVRN’s 6-Month AI Campus Deployment Timeline — phase by phase breakdown of the modular AI campus build process.
- Does Your Land Qualify for a Sovereign AI Campus? — SAVRN’s site evaluation criteria for landowners and developers.
- The 49 Billion Gallon Mirage: AI Data Center Water, Verified — the closed-loop cooling architecture that ends the water question.
- SAVRN sovereign AI infrastructure — the integrated power, compute, and cooling doctrine.
- About SAVRN — the operator behind the modular AI campus model.
Ready to evaluate a modular AI campus for your workload? SAVRN runs a structured site and workload screen, typically inside 48 hours, that maps your power, land, and timing constraints to a deployable architecture. Engage with SAVRN to start the conversation.
Sources & Citations
Every quantitative claim in this piece traces to a named, verified primary source. URLs verified at time of publication. The full audit-grade citation record, with claim-by-claim source mapping and “cite this article” snippets, is maintained on the dedicated SAVRN sources page for this piece.
Primary research cited in this modular ai campus brief
- LBNL — Queued Up interconnection queue tracker. Lawrence Berkeley National Laboratory queued capacity tracker — primary source for U.S. interconnection wait times that drive the modular-vs-hyperscale deployment economics.
- IEEE Spectrum — Modular Data Center coverage. IEEE Spectrum review of modular data center deployment — independent reporting on prefab and modular construction speed advantages.
Supporting frameworks, regulators, and industry data
- CreditSights — Technology Hyperscaler Capex 2026 Estimates. CreditSights aggregated estimates of hyperscaler 2026 capital expenditure — the baseline against which the modular campus capital efficiency is benchmarked.